
AWS Architecture This article will show a bird’s eye view of an asynchronous web application architecture and what AWS services an architect will use when building such a project. This architecture will not cover every detail or situation but should give a general view and understanding.
Before diving into schematics, let’s cover a little about what an asynchronous web application is and the difference between an asynchronous web app and a synchronous one.
In a synchronous web app, you call a web service, and then you have to wait until that service finishes the job and replies. All other operations will have to wait until that service responds.
In an Asynchronous type, you call a web service, but you don’t have to wait for a response. Instead, when a reply is received, the execution will jump to the callback function.
These applications separate client requests from application requests while continuously delivering updated application data to users.
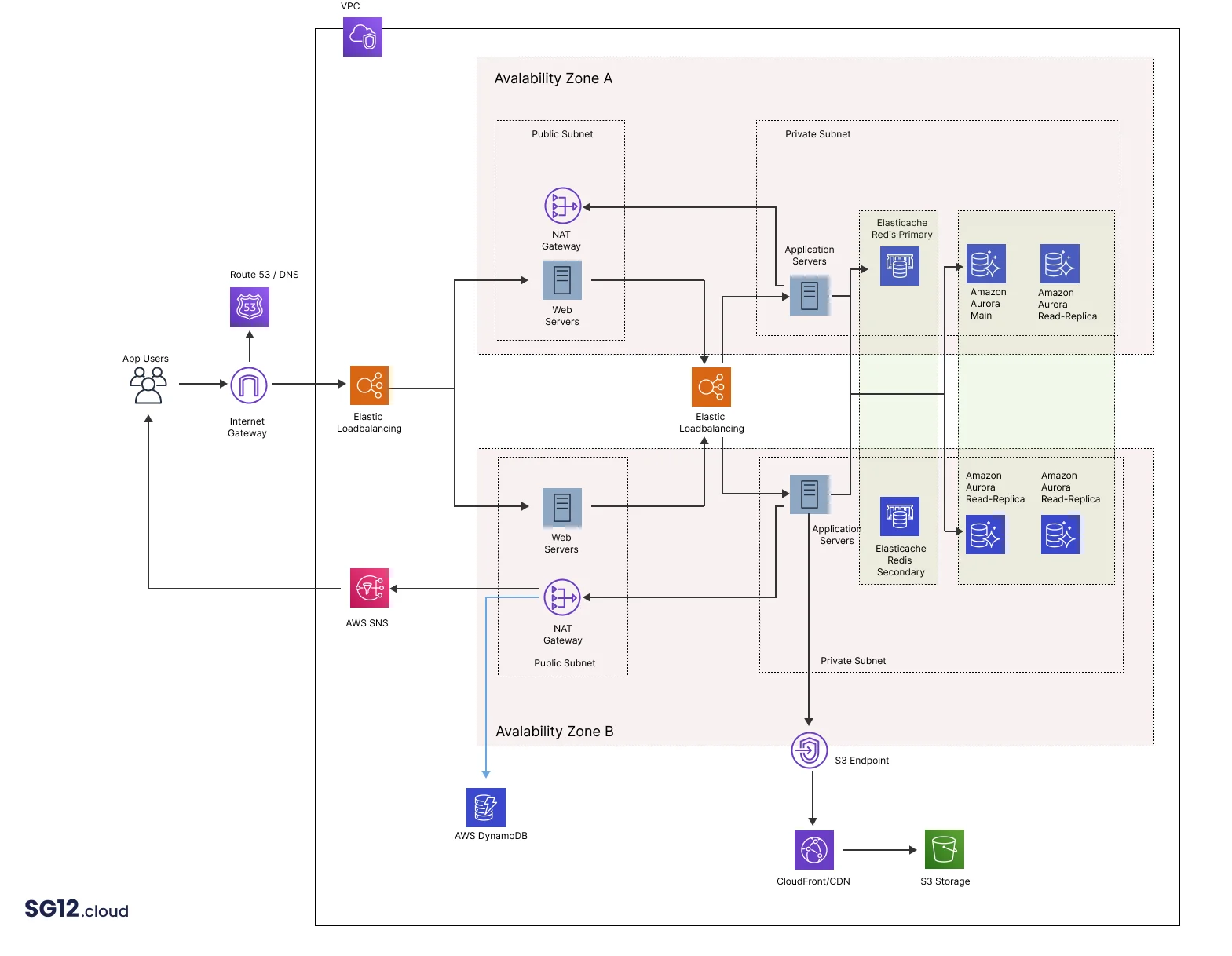
The first service we will employ is Route 53.
Route 53 is the DNS service from AWS and will help your users discover the application endpoints. Besides DNS resolution, this service can help you with route health checks or it can route visitors to specific endpoints according to geographical position or network latency.
Elastic Load Balancing
fter the visitors hit the internet gateway and pass via Route 53, they will end up on an Elastic Load Balancer. There are two types of load balancers you can use here: an application load balancer that uses HTTP or HTTPS for routing or a network load balancer that operates at a network level.
In most cases, you will probably end up with an application load balancer with the traffic distributed to the web application servers.
The architect will deploy the application resources in a VPC.
Because our goal is to have a high-availability application, we will deploy two availability zones: availability Zone A and availability Zone B.
We will use these two zones to ensure that our application will still be available if something happens in one of them. For example, if a catastrophic event occurs in zone A and the resources are not reachable, the load balancer will not send any more traffic to that area.
We will deploy two subnets in each zone: one public and one private. We will deploy resources accessible to end users, like web servers in a public subnet. In contrast, in a private subnet, we will deploy application resources, databases, and other services that need to remain private.
The Public & Private Subnets
In the public subnet, we will have our web servers. These are EC2 machines that are part of Auto Scaling Groups spawned over multiple availability zones. The autoscaling group will deploy more Ec2 instances when you receive extra traffic or requests. The machine’s number will scale up and down according to specific parameters (like CPU usage).
These web servers are entry points to our application, but they will not handle application logic. In this case, our application will use them only for the front interface.
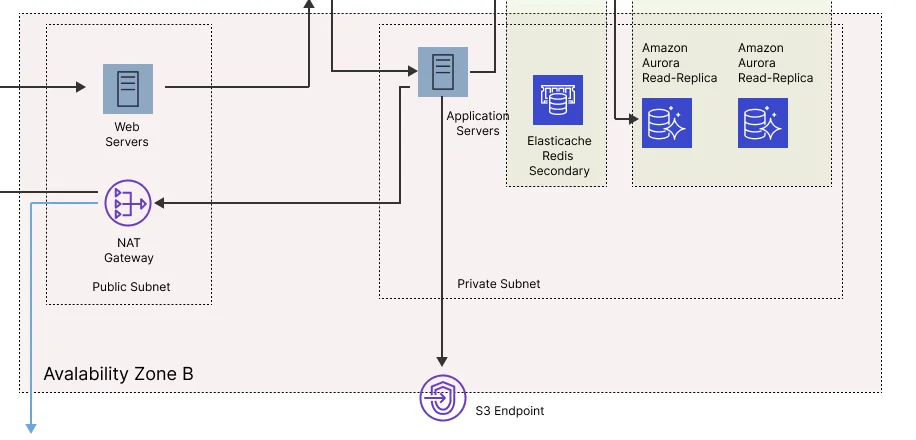
In the public subnet, we will also have a NAT gateway. The resources deployed in the private subnet will use the NAT gateway to get updates or other operations.
The servers from the private subnet will not be accessible from the public internet (hence the NAT gateway in the public subnet), and this isolation will enhance the security of this application.
To recapitulate – at this point, we have an Elastic Load Balancer that balances traffic between 2 availability zones. Each zone has a public subnet (with front-end web servers) and a private subnet.
The web servers from the public subnet will handle the initial user requests and will pass those to a second Elastic Load Balancer. This ELB will distribute the traffic to the application servers and provide an additional layer of security.
The application web servers are the ones that will handle all the business logic, and of course, they are also part of Auto Scaling groups. Therefore, their number will increase and decrease according to the processing load.
Databases – SQL /NoSql
If your app requires a SQL-like database, you could deploy an Amazon Aurora in the private subnet. AWS Aurora is a MySQL-compatible database that provides high read, and write-through output with up to 15 low-latency read replicas.
These servers will probably need to work with some databases. Depending on the application, you may need to use a MySQL-like database, NoSQL one, or both.
Along with the central Aurora database, we will also deploy additional read replicas in both availability zones (private subnets) to ensure that our application servers can always read and write the data.
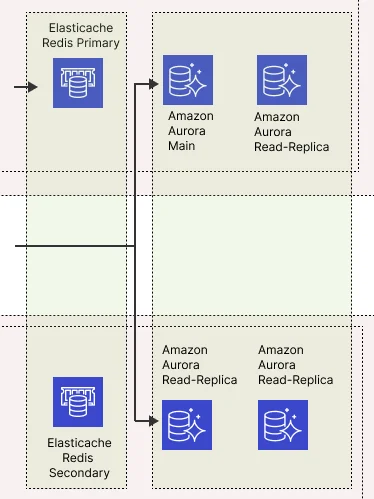
As a good practice, we will also use the Elastic Cache service. In this case, we could deploy a Redis cluster that spawns over multiple availability zones. This system will keep data query results in memory and provide milliseconds latency while protecting the databases in case of too many requests.
The application servers from both zones will talk only with the primary Redis. The second one will stand by just in case something goes wrong with the primary.
You don’t always need to deploy a cache component, but if you have many similar queries, it’s a good idea to have it in use. And also need to be aware that this high availability pattern comes with extra cots.
With this architecture, the application server will first query the Elasticache cluster.
If the cache exists, we will return the value to the server. If not, we will make a query to the database. Once we get the result, we will save it in the cache for further use.
The second database option we can deploy is the NoSql one. In this case, we can use a Dynamodb database. This database can scale over multiple servers and availability zones, and since it is a managed service, you don’t need to deploy and maintain the actual servers.
To keep things secure, we will also deploy a VPC endpoint as a safe path to the DynamoDb database.
SNS
This service is needed when you push notifications back to your users. For example, if you need to send messages like “we finished processing your video” or “you have a new message,” you will use the SNS service. This one has native integrations with OS, Android, etc., so it’s straightforward to integrate with any web or mobile application.
CloudFront and S3
Any application assets like images or video files will be stored using S3 buckets. To keep a secure architecture, we will interact with these assets via an S3 endpoint and ensure the buckets are not public.
Furthermore, we will restrict access to these assets only via CloudFront URLs. CloudFront is the CDN service from AWS and will distribute the application resources to nodes worldwide.
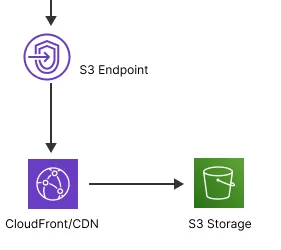
This way, users spread in different geographical locations will benefit from a low latency when querying for these objects.
Once you have all services in place and configured correctly, you will have a highly scalable and resilient architecture. If you have a peak in traffic, the auto-scalable groups can adjust, and your servers will be safe.
At the same time, if something catastrophic happens in one availability zone, your ELB will route the traffic to the other functional zone, and you will not suffer from downtime.


