
AWS lambda is a de-facto synonym with serverless. Since its release in 2014, AWS Lambda has become an essential tool for developing a serverless architecture in the AWS Cloud environment.
If you go over the Amazon specification, you will find that Lambda is an event-driven computing service that lets you run code/applications without needing servers.
Lambda functions can be called from most of the AWS services, and the best thing is that you will pay only for what you use.
This article aims to explain the techniques you can use to optimize the run of a Lambda function from both cost and latency perspectives.
Before we start
Any optimization process must start with a measurement one. Only after you can measure and have some complex data can you decide if it is worth optimizing and what is the best approach.
You may get a 0.1 ms speed improvement on your Lambda function, but if you spent a week trying to do so, it might not be worth it. And the actual savings could be only 10 cents per month.
Another mandatory thing you need to do is to go over your bill. You may look in the wrong place if most of the expenses are generated by EC2 instances. So look over the detailed billing report and decide after.
Setup Monitoring Before Optimization
As explained above, measurement is the first step in any optimization process. Every service you are using in a serverless environment will generate a set of metrics that you can use to measure the application’s performance and stability.
For example :
Throttles – the number of function invocations that did not result in actual code being executed. The are several factors that can cause this, and you can include here the account limitation, which is 1000 concurrent execution (can be increased by request)
Invocations – this is the total number of requests received by a function. Some functions will be triggered more often than others: consider a login function vs. a register function. So it’s a good idea to start optimizing with the most used parts.
Duration – This is the time required by your code to be executed. So it is obvious you should look over the functions that take longer to complete.
Error – the total number of errors generated by a particular function.
A special note: AWS X-ray
Aws X-Ray is not a free service; however, you may find out that it can be precious. It generates traces for a subset of requests and will present you with a visual interface to help you investigate all kinds of problems.
That being said, here are nine things you can do to optimize Lambda functions:
A special note: AWS X-ray
Aws X-Ray is not a free service; however, you may find out that it can be precious. It generates traces for a subset of requests and will present you with a visual interface to help you investigate all kinds of problems.
That being said, here are nine things you can do to optimize Lambda functions:
1. Pick the correct memory size for your Lambda Function.
When setting up your Lambda function, you do not have the option to choose the CPU or the Memory allocated. Instead, you get a single setting called Memory which is the Memory available for your Lambda function during invocation. AWS will then use that number to determine the CPU power allocation.
When setting up the allocated Memory, you need to be aware that there is a tradeoff – functions with larger memory size will cost more to run, but at the same time, they will be executed much faster.
If you need clarification on the memory value, you can use services like AWS Compute Optimizer. This service uses machine learning to analyze your metrics and give optimization advice for your EC2 fleet, Auto Scaling groups, EBS volumes, and Lambda functions.
Additionally, you can use 3rd party tools like AWS Lambda Power tuning to help you get the correct numbers. Find how in this article.
2. Minimize deployment artifact size
Every time a Lambda function starts, it must execute a series of steps.
- Lambda will download your code
- A new executing environment will be created (unless a warm one is already present)
- The “init code” is executed. Please note that the init code is everything that is outside the handler function
- The handler code is executed.
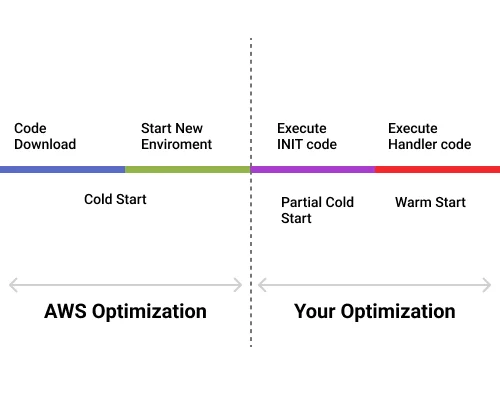
The first two steps are called “Cold Start,” and while you will not be charged for the time it takes Lambda to prepare the function. However, the time will be added to the overall latency.
After your code is executed, the environment where the function runs will be frozen and retained for a certain period. Then, if another request comes, Lambda will use the already-created environment without downloading the code again.
And, of course, you will get a faster response. This is called a “warm start.”
Special Note: Cold vs. Warm Start in Lambda
If you look at the steps above, realize that the first thing you can do is ship less code. While AWS Lambda has a limit of 250MB per deployment, it does not mean you should use it all – so load only the modules/libraries needed. The less code you add to a function, the faster it will be downloaded and executed during a cold start.
Another good practice is to avoid building large monolith functions. Instead, create small functions focused on a single thing, like inserting or deleting an item in a Dynamo.
3. Create Predictable start-up times with Provisioned Concurrency
When your Lambda function runs “on demand,” the latency profile may vary from invocation to invocation since the time to execute depends on the need for a cold start. However, this difference in latency may be something you try to avoid.
If that’s the case, you may use the “Provisioned Concurrency” feature, which allows more precise control. This feature will keep your functions initialized and ready to respond in milliseconds and on any scale.
Turning on this feature will not require code modifications however will add an extra cost. You can find out more about how you can configure it in this article.
4. Protect downstream resources with reserved concurrency
While reserved concurrency guarantees the maximum number of concurrent instances for a Lambda function, there may be a time when too many of them can hurt your downstream resources.
Your Lambda can call a legacy API or an external resource that is not able to handle more than x requests per second. Setting the correct number of concurrencies ensures that your downstream resources will be manageable even if your function is called many times.
5. Optimizing static initialization and code logic
Lambda Static initialization happens before the handler code is executed. This is the “INIT” phase, which occurs outside the handler.
During this period, libraries and dependencies are loaded, or we set up & initialize connections to other services.
According to AWS, this part is one of the largest latency producers. Besides, It is something only developers can control and can have a substantial impact during a cold start.
There are some things a programmer can do to optimize the code. The first is to rearchitect a monolith function into multiple and specialized ones with less INIT code.
It is also important to load only the libraries and dependencies that that particular function will use. Any extra weight will increase your code latency.
Avoid global scope for variables
Global variables should be avoided since they retain their values between invocations (on a warm start).
If your function has a global variable that is used only for the lifetime of a single invocation, then you can use one that is local to the handler.
This technique will prevent global variable leaks across multiple invocations and improve static initialization.
Define libraries outside the handler.
The code that loads a library should always be placed outside the handler. It will be executed on every invocation, if not outside the handler. If it is outside the handler, it will be performed once the environment is created (again, we assume a warm environment).
Use lazy loading for DB connection.
Define the database connection object outside the handler. Then inside the handler, test it and initialize it if it is null. This way, the database connection will be made only on the first run, and the connection object will be available on the rest of the invocations.
General code optimization
Try to optimize the CPU-heavy algorithms your function uses, look for faster libraries and only get the data you need from databases (For example, use Query to fetch a single item from Dynamo and not Fetch).
6. Set conservative timeouts
To correctly manage the performance and latency of a Lamda, you should set conservative timeouts. For example, the maximum timeout for a function is 15 minutes, and you may be tempted to select the max value to avoid timeouts.
However, this is not a good decision since performance issues may remain undetected, and costs could rise accordingly. As a rule of thumb, if a lambda function should be executed in under one second, then the timeout should be set accordingly.
7. Pick the correct language.
When building a Lambda function, AWS allows you to choose between several programming languages. And, of course, as a developer, you should pick the comfortable one.
However, you need to know that runtimes like C# or Java have a much slower initiation time than Node.js or Python. At the same time, the execution time is much faster once the environment is initialized.
So in case you have warm environments (provisioned concurrency), you may want to write the code in one of these languages to improve function latency.
8. Take advantage of multi-threaded programming.
This step is heavier depending on your skills and is easier said than done. However, if you know, it can be an option since optimizing the workload in parallel or multiple VCpu cores will lower the latency and costs.
This is a complex topic; we will not cover more details here. But you can find online resources about this topic.
9. Optimize the CloudWatch Log costs
What does Cloudwatch have to do with Lambda optimization? It is simple: the more you log in to Lambda, the more you pay to AWS.
While this step will not help improve the function latency, it may result in lower running costs.
Now, logging is essential. If done correctly, it will help you discover and fix bugs more efficiently, save time and increase productivity. But too much logging can hurt your bill. So it would be best if you found a balance on this matter.
There is also a technique you can use to lower the Cloudwatch bill.
You can store all your logs in Memory and not push them to STDOUT by default. But if an error appears, you will send those logs to Cloudwatch. If the function is executed correctly, the records are not set to CLoudwatch.
Why this technique may not give you the best view of your function execution will help you with the AWS bill.


