
Whether on-premises or in a cloud environment, there are three main types of storage: block storage, file storage, and object storage.
There may be different hardware that powers that storage, and the implementation may be different also. However, the fundamentals are the same for each type, regardless of the type or the storage location.
These are the three types:
Block Storage
Block storage is a basic type of storage ( raw storage) where a device, like a disk, is prepared and connected to a computer to store data. It is divided into fixed, continuous sections known as blocks. These blocks are the fundamental units used to keep data on the device.
The storage hardware can be solid state drives or SSDs, hard drives or HDDs, or the new type of device called NVMw – Non-Volatile Memory Express. Besides the individual storage devices, you can deploy block storage on SAN systems (storage area networks).
This storage is primarily used by operating systems or applications that manage them.
Use Cases: Databases, enterprise applications, virtual machine file systems.
File Storage
File storage is a system that uses block storage as its foundation, often working as a shared space or server for files. It is set up through an operating system that organizes and handles the process of saving and retrieving data to and from block storage devices. The term “file storage” refers to its primary function of holding data in the form of files, usually organized in a structure resembling a tree of directories.
Server Message Block (SMB) and Network File System (NFS) protocols are the two main ways to connect and work with file storage. These protocols let computers and servers talk to each other over a network, allowing you to use server resources and share&modify files remotely.
The operating system uses these storage protocols and manages how files are stored and accessed. This OS could be on a Windows Server, Linux, or a specific operating system designed for network-attached storage (NAS) devices or NAS systems that work together.
Use Cases: Shared drives, user directories, application configurations.
Object Storage
Object storage is another system that uses block storage as its foundation. It is set up by an operating system that organizes how data is saved & read from block storage devices.
The term “object storage” is used because it stores data inside a binary object, which means it treats all data the same without sorting it into different types. Object storage has metadata – data about data, including file type and other helpful info.
An object consists of many blocks put together in a set size. If the files or data are small, they’re kept inside one object at the binary level. For bigger files, the data is distributed over several objects.
Object storage is known for making sure files are always available. Some systems have features like keeping different file versions, tracking files, and managing how long files are kept.
Use Cases: Web applications, content delivery, backup and archiving, data lakes.
This article covers block storage, a storage type that is present on all cloud service providers. While the marketing names and some functionality differ, the core principles and functionality remain the same.

AWS
The AWS block storage includes two kinds: storage that comes with Amazon Elastic Compute Cloud (Amazon EC2) instances and Amazon Elastic Block Store (Amazon EBS).
Amazon FSx for NetApp ONTAP provides block storage services through the iSCSI protocol. This service uses NetApp’s software tools and management system. For those looking for a solution that integrates with NetApp’s system, block storage is offered within the Amazon FSx service.
Amazon EC2 instance store
An instance store offers short-term storage directly connected to the host computer running your instance. While it might seem similar to Amazon EBS at first glance, it’s more like having a hard drive plugged straight into the computer. This setup allows rapid access to the storage, almost instantly, from the EC2 instance.
Only certain types of Amazon EC2 instances come with instance stores. The type of instance you choose decides what kind of storage you get. How big these stores are and how many you can have depends on the type of EC2 instance you pick.
Instance stores are the solutions for cases like :
- Storing data that gets updated often, like buffers, caches, scratch data, and temporary files.
- Keeping data copied across many instances, for example, in a group of web servers that share the load.
- In some situations when you need extremely low latency on data IO operations
However, instance stores are not the best choice for your storage needs. Because they are temporary storage, they don’t get copied or distributed across different devices to make them more reliable or available. If the EC2 instance they’re attached to is stopped or deleted, the instance store goes away, too.
The data stays there as long as the EC2 instance is running and if the instance restarts, whether on purpose or by accident. But you’ll lose it if the disk drive breaks, the instance stops, goes into hibernation, or is terminated.
It is not a good idea to use an instance store for important data you need to keep for a long time. A more reliable storage option like Amazon EBS is the better solution to keep your data safe over the long term.
Amazon EBS
Amazon EBS is a user-friendly, high-performance storage service for blocks of data. It’s designed to work with Amazon EC2 instances, handling large amounts of data and transactions, regardless of size.
AWS suggests using Amazon EBS for low-latency operations on data that needs to be stored for a long time. EBS volumes are great for primary storage needs, like file systems, databases, or any program that needs to make small, detailed changes and use storage at the most basic, unformatted level.
These volumes act as basic, raw blocks of storage, and you can attach them to EC2 instances as EBS volumes. Once connected to an EC2 instance, EBS volumes function as standalone storage that doesn’t depend on the instance’s lifespan.
Amazon EBS offers various volume types, allowing you to find the right balance between cost and performance. Whether you need quick access times for demanding database tasks like SAP HANA or high data transfer rates for big projects like Apache Hadoop, EBS has options.
You can backup EBS volumes to Amazon Simple Storage Service (Amazon S3) using EBS snapshots that follow automatic rules. And you’re charged only for the storage and resources you use, making it a cost-effective choice for your storage needs.
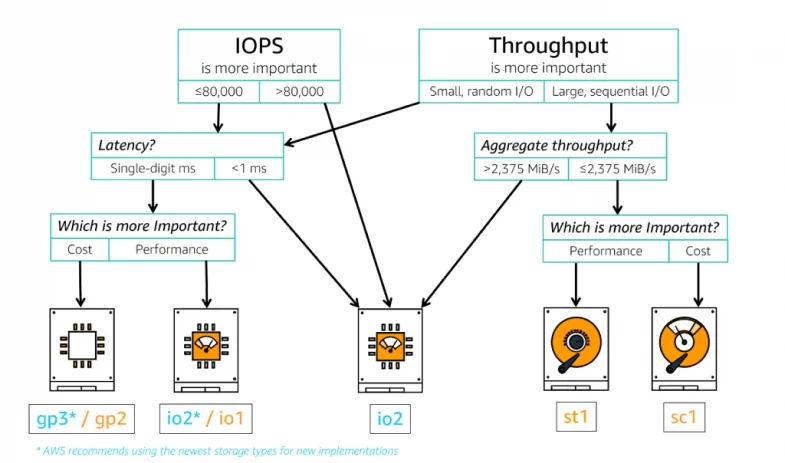
EBS Volume Types
Amazon EBS offers different kinds of storage that help you balance the speed and cost of various apps. There are two main types: storage that uses SSDs, which is fast and great for things like databases, virtual desktops, and starting-up systems, and storage that uses HDDs, which is better for jobs that move a lot of data around(high throughput), like analyzing big data or processing logs.
SSD-based volumes come in two types: general-purpose SSDs and Provisioned IOPS SSDs. General Purpose SSDs (gp3 and gp2) offer a good mix of cost and speed for apps like virtual desktops, testing environments, and online games.
Provisioned IOPS SSDs (io2 and io1) are the top performers for demanding tasks, such as running SAP HANA, Microsoft SQL Server, and IBM DB2.
For HDDs, there are Throughput Optimized HDDs (st1) used for frequently accessed, throughput-intensive ops, and Cold HDDs (sc1) that are cheaper and best for storing data you don’t need to access all the time.
Use Cases
Some of the common use cases are :
Enterprise Applications: EBS supports enterprise applications like SAP, Oracle, and Microsoft SharePoint with the required performance and reliability, making it suitable for critical business operations.
Databases: EBS is ideal for relational and NoSQL databases like MySQL, PostgreSQL, Oracle, and MongoDB due to its low latency and high-throughput performance, especially with Provisioned IOPS volumes for intensive transactional.
Big Data and Analytics: EBS provides the scalability and performance needed to process large datasets quickly for big data analytics applications, such as Hadoop and Spark.
The most popular way for organizations to move from their data centers to the cloud is “lift and shift,” or rehosting. This method involves transferring an app and its data to the cloud with minimal changes, using services that work similarly to what was used on-premises.
Choosing the lift and shift method speeds up the move to the cloud. With Amazon EBS, you can mimic your current setup by making storage volumes and connecting them to cloud computers. You will also be able to change the size and speed of your storage easily, helping you fine-tune your application once it’s on AWS.
Scaling and Elasticity
You can set up a file system on these volumes or use them just like any block device (for example, a hard disk). Plus, you can adjust the settings of an EBS volume connected to an EC2 instance on the fly, which you can’t do with regular hard drives with fixed sizes.
You can switch between EBS volume types, adjust their performance, or expand their size without interrupting your essential services.
Data Durability and Availability
Amazon Web Services EBS offers high data durability and availability, ensuring that your critical data is safe and accessible when needed. EBS achieves this by automatically replicating data within a single Availability Zone (AZ) to prevent data loss due to failures.
With a durability rating of 99.999% for EBS volumes, AWS minimizes the risk of data loss, making it a reliable choice for storing important information. Furthermore, EBS’s built-in redundancy and snapshot capabilities allow for easy backup and recovery, enhancing data protection.
Security and Compliance
Amazon EBS encryption lets you secure your EBS data volumes, boot volumes, and snapshots without the hassle of setting up a complex key management system. It protects your stored data by encrypting it, using either keys provided by Amazon or ones you make and control through AWS Key Management Service (KMS).
The encryption happens on your EC2 instances, meaning your data is also safe when it moves between your EC2 instances and your EBS storage.
Also, you can control who gets to access your EBS volumes through AWS Identity and Access Management (IAM), which allows you to manage permissions for your EBS storage.
EBS Snapshots and Data Backup
You can make backups of your Amazon EBS volumes by taking snapshots at specific moments. A snapshot only saves changes made since the last snapshot, making it a quick and cost-effective way to back up.
These snapshots are kept in Amazon S3, but you can’t see or access them directly; you must use the Amazon EC2 console or API to handle them.
A snapshot holds everything needed to copy your data onto a new EBS volume as it was at the snapshot’s time. When you make a new volume from a snapshot, it starts as an exact copy of the original volume but gets its data filled in as you use it.
If you try to use data that’s not yet loaded, the volume immediately fetches it from Amazon S3 and keeps loading the rest quietly in the background. Deleting a snapshot only removes the unique data, not what was shared with other snapshots.
AWS Backup and AWS Data Lifecycle Manager (DLM) are two services Amazon Web Services offers for managing data backup and lifecycle policies. AWS Backup provides a centralized service to automate and manage backups across AWS services. It simplifies backing up data by allowing users to configure and audit the AWS resources they want to back up from a single place, ensuring compliance with backup policies.
On the other hand, AWS DLM is specifically designed to automate the lifecycle management of Amazon EBS snapshots and EBS-backed AMIs. It enables users to create policies that automate snapshot creation, retention, and deletion, helping to manage costs and comply with data retention policies.
AZURE
In Azure, every new virtual machine comes with two types of storage: one for the operating system and one for local storage (you don’t have to pay for the local storage).
The storage for the operating system is typically 127GB; it can be less for certain types and is billed at the standard rate.
Like on AWS, we have two main block storage disks: the equivalent of AWS instance storage called ephemeral OS disks and the AWS EBS equivalent called Azure managed disks.
Ephemeral OS disks
Ephemeral OS disks are set up directly on a VM’s local storage and are not saved into Azure Storage. They work best for applications that don’t keep data permanently, especially those that can quickly recover from VM disruptions but need quick setup or recovery times. Benefits include faster access to the OS disk and speedier VM setup or recovery processes.
Key advantages of using ephemeral disks include:
- They are a good fit for applications that don’t store data permanently.
- Compatibility with a wide range of images available through Azure.
- The ability to quickly reset VMs to their initial state.
You have options for where to place these disks, such as the VM’s OS cache or temporary storage areas, thanks to a feature called DiffDiskPlacement. This allows for flexibility in managing resources, especially with Windows VMs, where the system’s page file is strategically placed on the OS disk to optimize performance.
Azure managed disks
Azure managed disks offer block-level storage volumes that Azure oversees and are designed for use with Azure Virtual Machines. Think of them as the cloud equivalent of a physical disk on a traditional server but fully virtualized. Setting up a managed disk is straightforward: you choose its size and type, and Azure takes care of the rest, from provisioning to management, eliminating the need for manual storage management tasks.
Volume Types
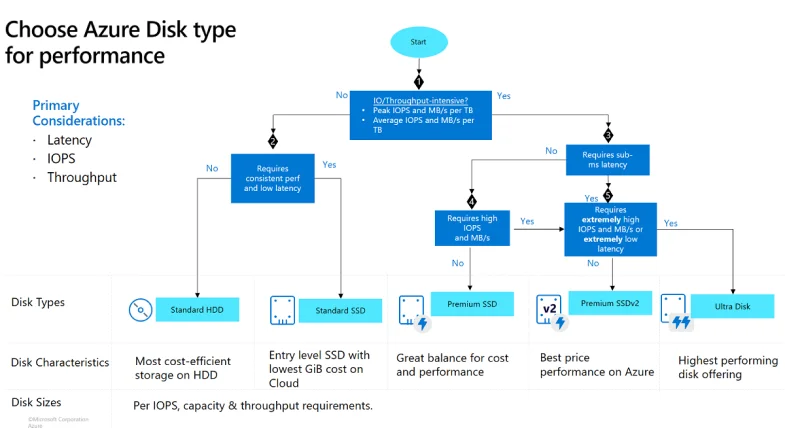
Azure Managed Disks provide a range of five disk types designed to cater to various needs and use cases. Each type offers different performance and pricing levels, allowing users to select the most appropriate option for their specific requirements, whether running everyday applications or needing high-performance storage for intensive computing tasks.
Ultra disks
Azure ultra disks offer the peak performance level for Azure virtual machines (VMs), allowing for on-the-fly adjustments to performance settings without needing to reboot your VMs. These disks are especially useful for handling data-heavy tasks like running SAP HANA, major databases, or workloads with many transactions.
Ultra disks are intended for use as data disks and must be initiated as blank disks. For the operating system (OS) disks, it’s recommended to use Premium SSDs. The capabilities of ultra disks include a maximum size of 65,536 GiB, with the ability to handle a throughput of up to 4,000 MB/s and achieve up to 160,000 IOPS, making them a powerful choice for your most demanding applications.
Premium SSD v2
Premium SSD v2 enhances Azure’s storage options by offering superior performance compared to the original Premium SSDs while also being more cost-effective. Users can adjust performance metrics such as capacity, throughput, and IOPS on the fly, making it easier to optimize costs and performance as demands change.
This makes Premium SSD v2 particularly effective for varying workload requirements, from high-transaction databases needing intense IOPS at smaller sizes to gaming applications requiring bursts of IOPS during peak times.
Suited for a wide array of applications, including SQL Server, Oracle, MariaDB, SAP, Cassandra, Mongo DB, big data/analytics, and gaming, these disks are versatile for virtual machines and containers that maintain state. They offer disk sizes of up to 65,536 GiB, with a maximum throughput of 1,200 MB/s and up to 80,000 IOPS.
Premium SSD
Azure Premium SSDs provide VMs with high-speed, low-delay storage, perfect for jobs requiring many input/output operations. These SSDs are ideal for essential applications running in production environments and are compatible with specific Azure VM types. With a maximum capacity of 32,767 GiB, they offer up to 900 MB/s in throughput and 20,000 IOPS, supporting demanding data workloads efficiently.
One of the standout features of Premium SSDs is their disk bursting capability, which allows for improved handling of sudden increases in IO demand. This feature is particularly beneficial for scenarios like system startups or when applications experience traffic bursts, ensuring smooth performance during these critical times.
Standard SSD
Azure Standard SSDs are designed for workloads requiring steady performance at a more modest level of IOPS. They stand out as a solid option for those transitioning from or used to the performance levels of traditional on-site HDD solutions. With improvements over standard HDDs in terms of availability, consistency, reliability, and latency, Standard SSDs enhance the performance and reliability of various applications.
They are well-suited for web servers, application servers with low IOPS demands, lightly utilized enterprise applications, and developmental or test environments. Available across all Azure VM types, Standard SSDs offer a cap of 32,767 GiB in disk size, with a maximum throughput of 750 MB/s and up to 6,000 IOPS, presenting a reliable and cost-effective solution for a broad range of uses.
Standard HDD
Azure Standard HDDs offer dependable, cost-efficient disk support for VMs handling workloads that can afford some latency. These disks rely on traditional HDD technology, leading to a broader range of performance fluctuations than SSDs. Standard HDDs aim to keep write latencies under 10 ms and read latencies below 20 ms for most operations, although performance may shift based on the size of the IO and the specific nature of the workload.
These disks are handy for development/testing environments and workloads that are not mission-critical. With universal availability across Azure regions and compatibility with all Azure VMs, Standard HDDs provide a maximum size of 32,767 GiB, a peak throughput of 500 MB/s, and up to 2,000 IOPS, making them a viable option for a variety of less demanding storage needs.
Scaling and Elasticity
With Azure disks, you can scale from just a few gigabytes to petabytes. You can adjust the performance as your business requires, using tiers and the ability to burst capacity to handle spikes in demand. With Azure Ultra Disk Storage and Premium SSD v2, you can set your IOPS, throughput, and storage size separately, ensuring top performance even at smaller scales. Setting up and managing your storage is straightforward—pick the type and size of disk that fits your needs.
Data Durability and Availability
Azure Managed Disks have two options for keeping your data safe: Zone-Redundant Storage (ZRS) and Locally Redundant Storage (LRS).
ZRS spreads your data across three different physical locations in a region, enhancing its availability more than LRS, which stores three copies of your data in one data center. Though LRS offers faster data writing because it operates within a single location, it’s less resilient to regional disasters.
For LRS, safeguarding against data center issues includes using applications that write to multiple zones and can switch over automatically. Regularly backing up data with ZRS snapshots and setting up cross-zone disaster recovery with Azure Site Recovery are also recommended, despite not guaranteeing instant data recovery (zero RPO).
On the other hand, ZRS ensures your data is safe even if a whole zone goes down, as it keeps your data replicated across three separate zones within a region. Each zone has a distinct facility with utilities, making ZRS highly durable.
In case of a zone failure, you can quickly recover by creating new disks from ZRS snapshots and attaching them to a VM, ensuring minimal disruption. ZRS is particularly useful for applications requiring high availability, like certain databases and distributed systems, offering an option to attach a shared disk to VMs in different zones for seamless failover.
This approach to storage redundancy in Azure allows for flexibility in planning disaster recovery strategies, balancing between immediate data availability needs and broader geographical resilience.
Security
Azure provides multiple encryption methods to secure your managed disks, ensuring the safety of your data across different scenarios:
- Server-side encryption (SSE): is a default setting that automatically encrypts your managed disk data (both OS and data disks) when stored. It’s known as encryption-at-rest. You can customize this using your keys with a Disk Encryption Set (DES). However, SSE does not encrypt temporary disks or disk caches.
- Encryption at host: enhances the default server-side encryption by encrypting temporary disks and disk caches. This option is available for Virtual Machines (VMs) and ensures even the temporary data and cache are encrypted at rest, providing an additional layer of security.
- Azure Disk Encryption (ADE): offers encryption for the OS and data disks within your VMs, utilizing DM-Crypt for Linux and BitLocker for Windows. This method integrates with Azure Key Vault, allowing you to manage your encryption keys and secrets effectively. ADE is designed to meet stringent security and compliance requirements.
- Confidential Disk Encryption: This is designed explicitly for confidential VMs, tying disk encryption keys to the VM’s Trusted Platform Module (TPM). This ensures the disk content is only accessible to the VM it’s attached to, offering high security.
Data Backup
Like in an AWS environment, Azure allows you to create snapshots of your disks. A snapshot in Azure is a complete, read-only version of a virtual hard disk (VHD). These snapshots serve as a backup at a specific time and can be invaluable for troubleshooting issues with virtual machines (VMs). Whether for an operating system (OS) disk or a data disk, snapshots capture the exact state of a disk when the snapshot is taken.
To manage the backups, you can use Azure Disk Backup, a cloud-native service designed to safeguard your data on managed disks with a straightforward, secure, and affordable approach. This service simplifies setting up disk protection, ensuring easy recovery in a disaster.
The core feature of Azure Disk Backup is its ability to automatically manage the lifecycle of disk snapshots. It does this by periodically taking snapshots of your disks and maintaining them for a duration determined by your backup policy. This hassle-free management eliminates the need for custom scripts or additional infrastructure, making it a cost-effective solution.
Disk roles
In Azure, VMs come with three types of disks: data, OS, and temporary. The data disk stores your application or essential data, and its capacity varies based on the VM’s size. The OS disk holds the operating system, pre-installed on creation, with a maximum of 4,095 GiB, though the usable size might be smaller due to partitioning schemes. Temporary disks provide space for transient data, like system temporary files, which might be lost upon VM restarts or maintenance. Each disk type serves a specific purpose, ensuring your VM operates efficiently and effectively.
Google Cloud Platform
Local SSD Disk
same as AWS instance store or Azure ephemeral disks
Local SSD disks are storage spaces directly connected to the computer running your virtual machine (VM). They are faster and can handle more data at once than regular storage options on Google Cloud. However, anything you save on a Local SSD will be gone if you turn off or remove your VM. You can add more than one Local SSD to your VM, but how many you can add depends on your VM’s power, measured in vCPUs.
Each Local SSD disk you add to your virtual machine (VM) has a set size of 375 GiB. If you need more space, you can attach several Local SSD disks when setting up your VM. How many disks you can add depends on your VM type and how many vCPUs (virtual CPUs) it uses.
Since Local SSD is designed for short-term use, you should save any data that needs to be kept longer on one of the long-lasting storage options.
Persistent disk
The AWS EBS / AZURE Managed disk alternative on Google Cloud is Persistent Disks. Persistent Disks provide block storage functionality, enabling virtual machine instances to access and use them as physical disks.
Persistent Disk volumes act like hard drives for virtual machines (VMs), but they exist on the network, not inside your computer. It means your data is spread out over many hard drives for safety and better speed, and Google Cloud manages all these details for you.
Since Persistent Disks are separate from your VMs, you can remove or switch them to different VMs and keep your data safe, even if you delete them. Also, the bigger the Persistent Disk, the better it performs. If you need more speed or space, you can make your Persistent Disk larger or add more of them to your VM anytime.
Volume Types
When setting up a persistent disk, you can choose from different types, including:
Balanced persistent disks (pd-balanced)
These are the middle ground between high-performance SSDs and the more cost-effective standard disks. They work well for most virtual machine sizes, providing the same top speed (IOPS) as the faster SSD disks but with a lower speed per gigabyte of storage.
This option is suitable for many regular applications, offering a nice balance between speed and cost, and is less expensive than the high-speed SSD option. These disks also use SSD technology.
Performance SSD persistent disks
Performance SSD persistent disks (pd-SSD) are designed for heavy-duty tasks like enterprise applications and high-speed databases, requiring quicker response times and more operations per second than regular persistent disks offer.
These disks are built for fast response times, often under ten milliseconds, although the exact speed can vary depending on the application. They use SSD technology to ensure quick access to data.
Standard persistent disks
Standard persistent disks (pd-standard) are suitable for tasks that handle a lot of data in order, like processing big datasets. They are based on traditional hard drives (HDD).
Extreme persistent disks
Extreme persistent disks (pd-extreme) are made for very demanding tasks that need a lot of fast and random access or quickly moving a lot of data. They are perfect for top-tier database jobs. With these disks, you can set up the desired speed in terms of operations per second. They use SSD technology for fast performance but are only compatible with certain types of machines.
Scaling and Elasticity
One of the key features of Persistent Disk is its ability to scale storage capacity without downtime. Users can increase the size of an existing disk on the fly, ensuring that applications can access the storage they need without interruption. This seamless scaling capability eliminates the need for planned outages or complex migration processes, enabling businesses to respond quickly to changing requirements.
Elasticity in Google Cloud Persistent Disk also extends to performance scaling. As the size of a Persistent Disk increases, its performance metrics, such as input/output operations per second (IOPS) and throughput, scale accordingly. This automatic performance scaling ensures that storage capacity grows and disk performance improves, allowing applications to handle larger workloads and more users efficiently.
Data Durability and Availability
When you create a persistent disk, you can choose between a single zone disk or a regional one.
Regional Persistent Disk is a storage service in Google Cloud that helps you set up highly available (HA) systems on Compute Engine. It makes sure your data is safe by keeping copies in two zones in the same region. This way, your data is still safe even if one location has a problem.
This type of storage is great for systems that need to be back up and running quickly after a problem (low Recovery Time Objective, or RTO) and can only afford to lose a little data if something goes wrong (low Recovery Point Objective, or RPO).
A regional Persistent Disk has two storage locations in its region for your data:
- The primary zone is where the disk is connected to your virtual machine (VM). This is in the same zone as your VM.
- The secondary zone is another location you pick within the same region.
Google’s Compute Engine keeps a copy of your disk in both places. Every time you add data to your disk, it immediately copies it to both locations to ensure your system is highly available (HA). The data in each location is spread out over several physical machines to keep it safe. This way, even if there’s a problem in one zone, your data stays safe and accessible because of these copies.
Security
Google Cloud Persistent Disk offers robust security features to protect data stored on its cloud infrastructure. At the core of its security model is automatic encryption, ensuring that all data at rest is encrypted without any required action from the user. This encryption applies to all Persistent Disks, providing a solid layer of protection against unauthorized access.
Google-managed encryption keys are used by default, offering a simple approach to encryption where Google handles the encryption and decryption processes transparently.
For organizations seeking more control over their encryption keys, Google Cloud provides the option to use Customer-Managed Encryption Keys (CMEK). With CMEK, customers can generate and manage their encryption keys using Google’s Cloud Key Management Service (KMS), allowing for an additional layer of security and compliance by enabling organizations to meet specific regulatory requirements.
Persistent Disk’s integration with Google’s Identity and Access Management (IAM) allows for fine-grained access control, enabling administrators to specify who can access specific Persistent Disks and what actions they can perform.
Data Backup
The core feature enabling backups is the snapshot capability, which allows users to create point-in-time copies of their disks. These snapshots can be used for backups, restoring data, or creating new Persistent Disks.
Snapshots can be automated through Google Cloud’s scheduled snapshots feature, allowing users to define policies for regular backup intervals. This automation guarantees backups are created without manual intervention, providing a consistent and up-to-date backup schedule that can be adjusted to meet specific RPOs.
There are three kinds of snapshots—standard, instant, and archive. The main differences between these snapshot types lie in how quickly you can recover data from them (RTO) and where it is stored.
Instant snapshots are the quickest to recover from and are saved on local disks, kept in the same area or region as the original disk.
Standard snapshots are faster to recover from than archive ones, while Archive snapshots take the longest time to recover data, but they are the most affordable in terms of storage costs.
Archive and standard snapshots are backups stored in different locations from the original disk, acting as remote copies of the disk data.
Conclusion
After we covered the main features of each provider block storage solution, we can conclude that they are very similar. Each provider offers two main types of block storage disks: one very fast but ephemeral and one for long storage that can be attached to one or multiple virtual machines.
Also, you have the option to choose between a cold storage disk, a high throughput one, a high IO disk, or an extreme performance one. While the names and performance numbers may differ, they will fall into one of those categories.
Disk snapshot is the way to do backups. Those incremental disk images are securely stored and can be used to recreate them in case of failures. You will also find complementary solutions like AWS Backup/Azure Disk Backup that will help you manage these backups.
Also, the same layered security approach is present. Create security policies so only authorized personnel can access the data and encrypt that data with customer or cloud provider keys.

