
File storage on premises
File storage is a hierarchical storage type that can provide access to a set of networked clients. The data is stored in files, directories, and volumes, and to access the data, you need to have the proper permission.
In on-premises architecture, they are called network-attached storage(NAS) and provide an access point to the network subsystems(and also cover data management, security, and fault tolerance)
File storage in the cloud
The file storage in the cloud follows the same principles as on-prem. But, instead of storing the files on NAS, you keep them in cloud resources by doing your setup or using managed services.
Here’s a breakdown of some common use cases for file storage:
Big Data Analytics: IT provides the necessary performance and consistency for handling machine learning (ML) and big data analytics workloads. It’s scalable and easy to use, making it suitable for tasks requiring large datasets analysis.
Web Serving and Content Management: With its scalability and durability, FS is ideal for web applications and content management systems. It can handle spikes in user demand by scaling the number of web servers dynamically, ensuring consistent access to files stored without manual reconfiguration.
Application Testing and Development: It is a centralized storage repository for development environments, enabling secure sharing of code and other files among team members. It facilitates collaboration and organization in the development process.
Media and Entertainment: Media companies benefit from file systems throughout the post-production pipeline. It provides high throughput and durability for ingesting and storing media content and shared access to compute resources for efficiently processing tasks.
Database Backups: FS is a reliable backup repository for Oracle, SAP HANA, and IBM Db2 databases. Many database backup applications prefer the NFS file system interface, offering high throughput and low recovery time objectives (RTO) for restoring backups.
Container Storage: It offers persistent shared access to a centralized file repository, making it suitable for containerized applications. It provides storage for containers running on platforms like Kubernetes.

AWS File Storage Services
AWS provides various options for sharing files among multiple users or systems based on your needs.
For managing file-related tasks on AWS, you can choose from different services like Amazon EFS, Amazon FSx for Lustre, Amazon FSx for NetApp ONTAP, Amazon FSx for Windows File Server, or Amazon FSx for OpenZFS. Each service is tailored to different use cases and workflows.
Amazon EFS
The AWS EFS is the original managed file-sharing service and is fully managed, elastic, and scalable.
It provides a scalable and elastic file system suitable for various AWS Cloud services and on-premises resources. The EFS can scale to store petabytes of data, and as a managed service, the necessary storage size is automatically allocated, eliminating administration tasks for you. Amazon EFS dynamically adjusts its capacity to meet changing storage needs, ensuring you don’t overprovision storage and only pay for the storage you use.
With Amazon EFS, your performance scales alongside your capacity. It can deliver impressive throughput of up to tens of gigabytes per second and handle over 500,000 IOPS (Input/Output Operations Per Second). AWS file system solution can accommodate increased performance requirements as your storage demands grow, ensuring your applications run smoothly without performance bottlenecks.
Performance Modes
There are two performance modes:
General Purpose:
- – The default performance mode and is well-suited for most workloads.
- – Recommended for latency-sensitive applications such as web serving, content management systems, home directories, and general file serving.
- – Ideal for situations where low latency is crucial, and the workload doesn’t require extremely high throughput or IOPS.
Max I/O:
- Recommended for workloads that need to scale to higher levels of aggregate throughput and IOPS
- This mode prioritizes maximizing throughput and IOPS at the expense of slightly higher latencies for file metadata operations.
- Well-suited for highly parallelized applications and workloads such as big data analytics, media processing, and genomic analysis.
- Provides increased performance capabilities for tasks that require intensive data processing and high throughput.
Throughput modes
Besides the two performance modes, the EFS offers two throughput modes to optimize performance based on workload requirements:
Bursting Throughput:
- The default throughput mode is suitable for most workloads.
- Performance scales with the size of the data stored on the file system. The larger the file system, the better the performance.
- Ideal for workloads where performance requirements vary over time or bursty workloads are common.
- With bursting throughput, you don’t need to provision throughput, making it explicitly convenient for dynamic workloads.
Provisioned Throughput:
- It is recommended for workloads needing higher throughput-to-storage ratios or requiring consistent performance.
- Provides higher levels of aggregate throughput for smaller file systems.
- Allows you to provision the throughput of your file system (measured in MiB per second) independently of the amount of data stored.
- Suitable for applications with predictable and consistent performance requirements, allowing you to allocate specific throughput levels based on workload demands.
Availability and Durability
AWS EFS (Amazon Elastic File System) is designed to offer high availability and durability by automatically replicating data across multiple Availability Zones to ensure fault tolerance and uninterrupted access. It guarantees 99.999% availability and provides the same level of durability as Amazon S3, storing data redundantly to protect against the loss of one or more Availability Zones.
Availability:
- Amazon EFS offers a 99.99% availability service-level agreement (SLA), ensuring your file system is highly accessible.
- It achieves this high availability by redundantly storing files and directories within and across multiple Availability Zones (AZs).
- When you write data to Amazon EFS, it’s replicated across three Availability Zones before the write is acknowledged.
- Even if one Availability Zone fails, Amazon EFS continues to provide the same level of service from the remaining Availability Zones, ensuring uninterrupted access to your data.
- This level of availability is particularly beneficial for businesses accustomed to operating within a single primary data center, providing resilience and continuity in the face of AZ failures.
Durability:
- Amazon EFS is designed for 11 nines (99.999999999%) of data durability, ensuring your data is highly protected against loss.
- Data redundancy across multiple Availability Zones guarantees that your files and directories are safely stored and protected.
- For additional data protection, Amazon EFS integrates closely with AWS Backup services, allowing you to create backups of your file systems.
- These backups are stored across multiple Availability Zones, further enhancing the durability and resilience of your data.
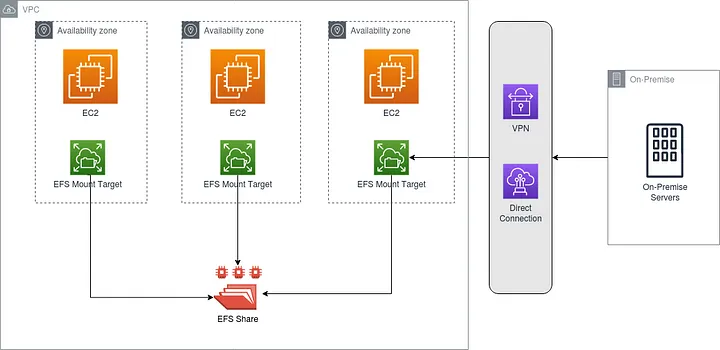
Security
AWS EFS provides comprehensive control over access to your files through various mechanisms:
Network Access Control:
- You can manage which network resources can access your file systems using VPC routing and security group firewall rules.
- Amazon VPC security groups enable you to restrict network access to Amazon EFS endpoints, allowing you to specify which IP addresses can communicate with your file system.
User and Application Access Control
- AWS Identity and Access Management (IAM) policies and Amazon EFS Access Points offer granular control over user and application access to your file systems.
- IAM policies allow you to define permissions for specific actions on Amazon EFS resources, controlling who can access and manage them.
- Amazon EFS Access Points provide a way to configure application-specific access to your file systems, simplifying access control for multiple applications.
- You can create IAM roles with specific permissions for managing file systems and grant them to users in your AWS account.
POSIX Permissions:
- You can utilize POSIX-compliant user and group-level permissions to regulate client access permissions to your file systems.
- These permissions allow you to specify which users and groups have read, write, and execute permissions on files and directories.
AWS Key Management Service (KMS):
- AWS KMS allows you to manage encryption keys to protect data at rest within the file system.
- You can use KMS to encrypt the data stored in Amazon EFS, ensuring data security.
- Transport Layer Security (TLS) can also encrypt data in transit when mounting the file system, further enhancing security.
Cost Optimization
With Amazon EFS, cost optimization is achieved through flexible pricing and storage management options:
Pay-as-You-Go Model:
You only pay for the storage your file system utilizes, with no minimum fee or setup cost.
Storage Class Options
Amazon EFS offers different storage classes, allowing you to choose the appropriate level of resilience, durability, and availability based on your requirements.
Standard: Provides multi-AZ resilience with the highest levels of durability and availability. It is ideal for workloads requiring high availability and reliability.
One Zone: Offers lower cost by storing data in a single Availability Zone. While providing additional savings, it maintains lower latencies due to data replication within a single zone.
Intelligent Tiering:
Newly created EFS file systems utilize intelligent tiering by default. This feature automatically optimizes storage costs by moving data to the lowest cost tier or optimizing for performance based on access frequency.
Frequently accessed data remains readily available, while infrequently accessed data is moved to more cost-effective storage tiers.
Lifecycle Management Policies:
You can define lifecycle management policies to optimize storage costs further. These policies allow you to automatically transition data between storage classes or delete data based on predefined criteria, ensuring cost efficiency over time.
Backup
AWS Backup:
- Configure, automate and monitor backups for AWS resources.
- Perform incremental backups for EFS, reducing backup time and costs.
- Ensure backup consistency by managing modifications during backup processes.
Amazon EFS Replication:
- Create replicas of EFS file systems in preferred AWS Regions.
- Continually sync data with low RPO and RTO.
- Initiate failover by deleting replication configuration for writable destination file system.
EFS-to-EFS Backup Solution:
- Automatically backup EFS file systems in all AWS Regions.
- Leverage CloudFormation for easy deployment, following AWS best practices.
- Utilize fpsync for consistent, granular, and incremental backups.
Azure File – sub-service of Azure Storage Account
Azure Files provides fully managed cloud-based file storage accessible through the SMB & NFS protocol and Azure Files’ REST API.
These file shares can be simultaneously mounted by cloud or on-premises deployments. SMB Azure file shares are accessible from Windows, Linux, and macOS clients, while NFS Azure file shares are accessible from Linux clients. Moreover, SMB Azure file shares can be cached on Windows servers using Azure File Sync, ensuring fast access to data close to where it’s needed.
Since Azure file shares are serverless, deploying them for production scenarios eliminates the need to manage a file server or NAS device.
Performance Modes
Azure Files provides four distinct tiers of storage, each designed to accommodate different performance and price requirements:
Premium:
- Backed by solid-state drives (SSDs), premium file shares deliver consistently high performance and low latency, typically within single-digit milliseconds for most IO operations.
- It is ideal for IO-intensive workloads like databases, website hosting, and development environments.
- Compatible with both Server Message Block (SMB) and Network File System (NFS) protocols.
Transaction Optimized:
- They are designed for transaction-heavy workloads that do not require the low latency of premium file shares.
- Utilizes standard storage hardware backed by hard disk drives (HDDs).
- Historically referred to as “standard,” transaction optimized distinguishes itself by the storage media type rather than the tier itself.
Hot:
- Tailored for general-purpose file-sharing scenarios like team shares.
- Utilizes standard storage hardware backed by HDDs.
Cool:
- Provides cost-efficient storage optimized for online archive storage use cases.
- Utilizes standard storage hardware backed by HDDs.
When choosing a storage tier for your workload, it’s important to assess your performance and usage needs. If your workload demands single-digit latency or you’re accustomed to using SSD storage media on-premises, the premium tier is likely the optimal choice.
However, if low latency isn’t a critical factor, such as with team shares mounted on-premises from Azure or cached on-premises using Azure File Sync, standard storage may offer a better cost-effective solution.
Availability and durability
Azure Files employs multiple copies of each file to safeguard the data upon writing. Depending on your needs, you can opt for various levels of redundancy. Currently, Azure Files offers the following options:
Locally-Redundant Storage (LRS):
- Each file is stored three times within an Azure storage cluster.
- Protects against hardware faults, such as malfunctioning disk drives.
- Vulnerable to disasters like fire or flooding within the data center, potentially leading to the loss of all replicas.
Zone-Redundant Storage (ZRS):
- Three copies of each file are stored across three separate storage clusters in different Azure availability zones.
- Availability zones consist of independent data centers with separate power, cooling, and networking infrastructure.
- Data is written to all three availability zones before being acknowledged, ensuring high resilience against zone failures.
Geo-Redundant Storage (GRS):
- Data is stored three times within an Azure storage cluster in the primary region.
- Asynchronously replicated to a Microsoft-defined secondary region and provides six copies of data spread between two Azure regions.
- In a major disaster, failover occurs, with the secondary region becoming primary and serving all operations.
- Asynchronous replication may result in data loss for operations yet to be replicated to the secondary region.
Geo-Zone-Redundant Storage (GZRS):
- Similar to ZRS but with geo-redundancy.
- Files are stored three times across three distinct storage clusters in the primary region.
- Writes are then asynchronously replicated to a Microsoft-defined secondary region.
- The failover process aligns with GRS, offering resilience against zone and regional failures.
Cost Optimization
Azure Files Reservations provide a cost-saving opportunity for Azure file share storage. By opting for Azure Files Reservations, also known as reserved instances, you can secure a discount on storage capacity costs when committing to a Reservation for one year or three years.
With Azure Files Reservations, you benefit from fixed storage capacity for the Reservation duration, leading to significant reductions in capacity costs for storing data in your Azure file shares. The amount of savings depends on factors such as the duration of the Reservation, the reserved storage capacity, and the tier and redundancy settings of your Azure file shares.
Azure Files does not offer built-in lifecycle management features like Azure Blob Storage. Lifecycle management policies are specific to Azure Blob Storage and are not directly applicable to Azure Files.
However, you can implement lifecycle management for Azure Files using custom scripts or Azure Automation Runbooks.
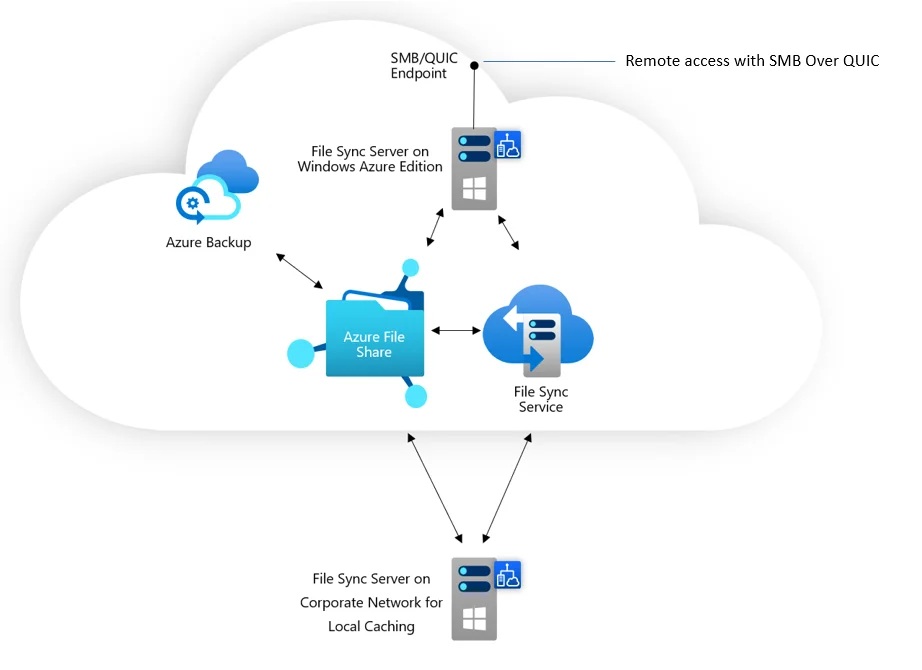
Security
Regarding security, specifically with the Enterprise File Sync (EFS) feature, Azure Files employs several robust mechanisms to ensure data protection and compliance with industry standards.
Firstly, Azure Files supports encryption at rest using Azure Storage Service Encryption (SSE), which automatically encrypts your data before storing it.
For data in transit, Azure uses Secure Sockets Layer (SSL)/Transport Layer Security (TLS) encryption to protect your data as it moves between Azure data centers and your clients, preventing unauthorized interception of files.
Access control is managed through Azure Active Directory (AD) integration, allowing permission management based on existing organizational identities. Additionally, role-based access control (RBAC) can be used to define more granular access policies, ensuring that only authorized users or services can access or manage the file shares.
Network security is further enhanced with the option to deploy Azure Files within a virtual network, utilizing private endpoints that can be used to access file shares.
Backups
Azure Backup allows you to secure your file shares through various methods, including the Azure portal, Azure PowerShell, Azure CLI, or REST API, offering flexibility in managing backups.
Snapshots of Azure file shares serve as point-in-time replicas that can be created manually or automatically through Azure Backup, allowing for the restoration of specific files as needed. Each file share can support up to 200 snapshots, offering multiple points for data recovery.
Being incremental, snapshots only record data changes since the previous one, improving space and cost efficiency.
Billing is based on the storage differences between snapshots, which supports the maintenance of numerous recovery points without significantly increasing costs, effectively meeting low Recovery Point Objective (RPO) needs.
Azure File Sync can also synchronize and back up data from on-premises file servers to an Azure file share, extending backup capabilities beyond cloud-only environments.
This integration provides:
- Versatile recovery options.
- Enabling the restoration of individual files or directories.
- A full-scale restore of the entire file share.
To recover, set up a new server on the primary site and connect it to the centralized Azure file share to access the data. Over time, Azure File Sync will manage local caching or cloud tiering of files according to its configurations, optimizing storage and access.
I’m just curios – are you reading this article ?Leave a comment if you do 🙂
Google Cloud Platform
Google Cloud’s Filestore instances are fully managed file servers that seamlessly integrate with various client types, including Compute Engine VMs, Google Kubernetes Engine (GKE) clusters, Google Cloud VMware Engine, and even on-premises machines.
After setup, you can scale them to meet changing demands without interruption in service. GCP uses the term instances, which is correct – every file system needs virtual machines that handle the file system management and networking. In the case of cloud services, you don’t have access to these instances, and like on AWS, you need to realize that they exist.
Filestore, offering persistent file storage, allows multiple application instances to access the same file system simultaneously, facilitating concurrent usage efficiently.
Filestore accommodates a range of file system protocols, including:
- NFSv3: Accessible across all service tiers, NFSv3 enables two-way communication between client and server, making it a versatile choice for various applications.
- NFSv4.1 (Preview): Offered within the enterprise and zonal service tiers, NFSv4.1 enhances security through client and server authentication, provides message integrity, and secures data in transit with encryption.
Each protocol is optimized for distinct scenarios, allowing for tailored solutions based on specific needs.
Service Tier
A Filestore instance’s service tier is determined by the specific mix of its instance type and storage type. After creating an instance, the service tier assigned to it is fixed and cannot be modified.
Basic Tier
A cost-optimized, general-purpose NFS storage system offering capacities ranging from 1 to 63.9 TiB. It allows scaling in 1 GiB increments or multiples thereof. The Basic HDD tier has static performance, while the Basic SSD tier sees a performance increase at the 10 TiB mark.
Zonal Tier
Designed for high-capacity NFS storage needs, this tier’s performance improves as capacity increases and is available from 1 to 100 TiB. For lower capacity needs, scaling is possible in 256 GiB increments or multiples; for higher capacity requirements, it scales in 2.5 TiB increments or multiples. Performance enhancement is linear and contingent on the selected capacity band.
Enterprise Tier
This tier offers a highly available NFS storage system ideal for mission-critical applications, with a capacity range of 1 to 10 TiB. It supports scaling up or down in tailored increments, ensuring high reliability and availability for demanding workloads.
Availability and durability
Filestore instances are engineered to automatically replicate data across multiple physical locations within a selected region, safeguarding against data loss due to hardware failures.
You should regularly check the usage of your Filestore instances to ensure their capacity aligns with your needs. If an instance previously set up for high-capacity SSD usage is not utilizing its full capacity, scaling down may be cost-effective. Conversely, if you approach the limit of your current capacity, increase it to avoid disrupting your applications.
You should also watch inode consumption. Each file on your Filestore share uses one inode, and running out of inodes means you can only add so many files, even if there’s unused capacity. Adding more capacity is the only way to increase inode count, though maxing out inodes typically only happens when storing many small files.
Filestore’s service tiers are built to optimize performance across multiple client VMs rather than for a single client VM. To fully leverage the performance capabilities of enterprise and zonal-tier instances, a minimum of four client VMs is required.
The base configuration of a scalable Filestore cluster includes four VMs. Communication occurs between each client VM and a single corresponding VM within the Filestore cluster, irrespective of the number of NFS connections per client established through the nconnect mount option. Consequently, if only one client VM is used, it will interact with just one VM from the Filestore cluster for all read-and-write activities.
Cost Optimization
If your Filestore usage is predictable, consider using committed use discounts where applicable. Committing to a certain usage level for a period can provide savings over on-demand pricing.
Use GCP’s monitoring tools to track the performance and capacity usage of your Filestore instances. Identify any inefficiencies or unneeded resources that can be scaled down or removed.
Security
Filestore does not offer Kerberos authentication for securing access to its instances. Instead, you can utilize Linux-based options to manage NFS access and leverage Identity and Access Management (IAM) for governing permissions related to instance operations, including creating, modifying, viewing, and deleting instances.
Encryption at Rest: Google Cloud Filestore automatically encrypts all data stored within the service, ensuring robust protection against unauthorized access.
Data in Transit Encryption: Supports secure connections to encrypt data moving between instances and the Filestore service, adhering to industry-standard protocols.
Access Control with IAM: Utilizes Google Cloud Identity and Access Management (IAM) for detailed access policy management, allowing administrators to control user and service access levels.
Integration with VPC: Offers network isolation by integrating with Google’s Virtual Private Cloud (VPC), facilitating private connectivity to file shares and enhancing security.
Backups
In GCP, you can create FileStores Backups and FileStore snapshots to back up your data. While similar in their purpose of data protection and recovery, they differ in several aspects:
Filestore Backup
- They are built for long-term data protection and archiving. Backups are typically used for disaster recovery scenarios.
- Backups are stored in a separate storage system from the primary data, often in a geographically distinct location, to ensure data safety in case of regional failures.
- Creating a backup may have a minimal impact on the performance of the primary system since it’s designed to be a background process, but this depends on the implementation.
- Restoring from a backup can be slower than a snapshot, as data might need to be transferred from a different storage system or location.
- Provides a point-in-time consistency, ensuring that the backup represents a coherent data state.
Filestore Snapshot
- Snapshots are primarily used for near-term data recovery, such as quickly reverting to a previous state or recovering from a user error.
- Snapshots are often stored within the same storage system or array as the primary data, making them quicker to create and restore.
- Typically, snapshots are designed to have a very low impact on the primary system’s performance, using a copy-on-write or similar mechanism to minimize overhead.
- Restoring from a snapshot is usually faster than a backup, as the data does not need to be moved over long distances.
- Like backups, snapshots provide point-in-time data consistency, but they are more suited for operational recovery than long-term archival.
Conclusion
As you can see, the implementation of the FS is quite similar for all three providers. Each service allows for easily mounting shared file systems across multiple servers, facilitating file sharing and collaboration within cloud environments.
A key similarity among them is their support for standard file protocols, such as NFS and SMB, ensuring broad compatibility with existing applications and operating systems.
These services provide automatic scaling to accommodate fluctuating file storage demands, guaranteeing that applications can access the storage they need without requiring manual intervention. This elasticity is crucial for optimizing costs and performance, particularly in dynamic computing environments.
Additionally, they emphasize security and compliance, offering robust data protection features such as encryption at rest and in transit, access control mechanisms, and integration with their respective cloud environment’s identity services.
Furthermore, they all support various performance tiers, allowing users to balance cost and performance by selecting the appropriate tier based on their workload requirements. This flexibility ensures that a suitable option is available, whether for high throughput for data-intensive applications or cost-effective storage for less critical data.
Besides the classic FS systems, there are other services like AWS FSX for Lustre or Azure NetApp files for high-performance computing (HPC) workloads or FSX for Windows File Server, but those are not the subject of this article.

