This post is the second part of the “Serverless pattern on Aws and Terraform article.” In the first part, we covered the project description and the process we followed to get a solution.
You can read the first article here: https://sg12.cloud/serverless-event-submission-pattern-using-terraform-and-aws/ .
The Terraform implementation code can be found here: https://github.com/crerem/event-submission-pattern-live
Now that our infrastructure design is completed, we can proceed with the implementation. Our “tools” are Terrafrom, Github, and Python for Lambda functions.
The Lambda function will not have the original code but a minimalist one. You can use this code (located in this GitHub) as a starting point for your project.
Terraform is an open-source infrastructure as a code(Iaac) tool that allows you to declaratively define the provision of infrastructure resources.
The AWS alternative solution is Cloudformation, and there is a continuous debate about who is the best tool. However, we will not get into that debate right now, and you can use whatever solution works best for you.
Let’s start by explaining how we organized our code and repository.
There are several ways to structure your repositories when using Terraform and Terraform workspaces. We will use a single repository(on GitHub) with a single workspace per repository directory for this project.
That means we will have a folder and a workspace for each development branch (ex devel and production). In each folder, we will have a “main.tf” (so “main.tf” for the production environment/folder and another “main.tf” for the devel environment/folder) from where we will “call” our Terraform modules.
Terraform modules are self-contained packages of terraform configurations, and you can use these modules in multiple infrastructure projects – and workspaces.
All the modules are declared in a folder outside the devel or production environment. This means that both devel and environment code will be able to reuse them and apply specific configurations with the help of variables.
Each module will have a “main.tf” – a file where we declare resources for that module, a “variables.tf” – a file where we set the input variables for that module and an “output.tf”- a file where we describe the outputs. These “outputs” can be used as input variables for other modules. For example, we use the SQS queue ARN as an input parameter for the API Gateway module.
As already explained, the production (or development folder) has two main files – “main.tf” and “variables.tf”. In the “variables.tf,” we declare variables that can have different values per development branch. So, for example, you can set an Environment label (devel or production) and use that later to tag your resources.
In the “main.tf” we instantiate our custom modules – from API gateway to lambda functions used in our serverless apps.
In the “API-gateway” module, we declare our API Gateway resources, but since this is just a demo/boilerplate project, we will use one resource with the path “example-resource.”
The most interesting part is where we declare this resource’s integration.
resource "aws_api_gateway_integration" "api" {
http_method = aws_api_gateway_method.api.http_method
resource_id = aws_api_gateway_resource.api.id
rest_api_id = aws_api_gateway_rest_api.api.id
integration_http_method = "POST"
type = "AWS"
credentials = aws_iam_role.api-gateway-to-sqs-role.arn
uri = "arn:aws:apigateway:${var.AWS_REGION}:sqs:path/${var.SQS_NAME}"
request_parameters = {
"integration.request.header.Content-Type" = "'application/x-www-form-urlencoded'"
}
request_templates = {
"application/json" = "Action=SendMessage&MessageBody=$input.body"
}
}In there, we add as the input URI the SQS where the API will send the request from the client. We also define a request validator to ensure the input for that particular route will have the right content type and parameters (the input must have an “orderID” and “OrderOwner” parameters – you can edit or remove this requirement).
Besides that, we needed to pay attention to the role that the API will assume and make sure that in the role policy, we add the permission to use the SQS queue.
In the “output.tf” file, we declared the sg12_rest_api_execution_arn, which contains the API execution URL.
Following the architecture diagram, we define the SQS queue module. In this one, besides the original receiving queue, we also declare a second queue resource – the “dead-letter” one.
The following module is the one that has the Lambda function, the one that tracks the SQS queue. The “aws_lambda_resource” will use a local zip archive for the source code, but you can use an S3 bucket URL if your situation/team requires it.
One thing to note is that this lambda function will need to poll the SQS queue and also send the data to the state machine that will handle the invoice processing. So in lambda code, we need to know the ARN of the step functions.
We do that by setting an environment variable that will hold the ARN of the Step function. Of course, we still need to cover the Step function creation, but Terraform will create the resources in the proper order, so you don’t need to worry about that.
We instantiate the environment variable via the resource “aws_lambda_function.”
environment {
variables = {
STEP_FUNCTION_ARN = var.STEP_FUNCTION_ARN
}
}And is retrieved in the Lambda function via
os.environ['STEP_FUNCTION_ARN'],Another thing that you should note in this module is the
resource “aws_lambda_event_source_mapping” that sets the SQS queue as an event source for this lambda function.
Finally, and probably the most complex thing in this architecture, is the step function declared in the module “step-function.”
The bulk of the code is in the declaration of the state machine – more precisely, in the definition part. However, writing a definition for the state machine directly in Terraform can be tricky.
So I suggest defining the state machine in the Step Functions Workflow Studio and copying the output code in Terraform when you are done.
For this demo implementation, we chose to do a simple step function implementation with a” Process Invoice” action that calls another Lambda function ( which is just a placeholder function), a notify action that will publish to an SNS topic, and the “Save to Dynamo” action that will insert a new record in a Dynamo Db table.
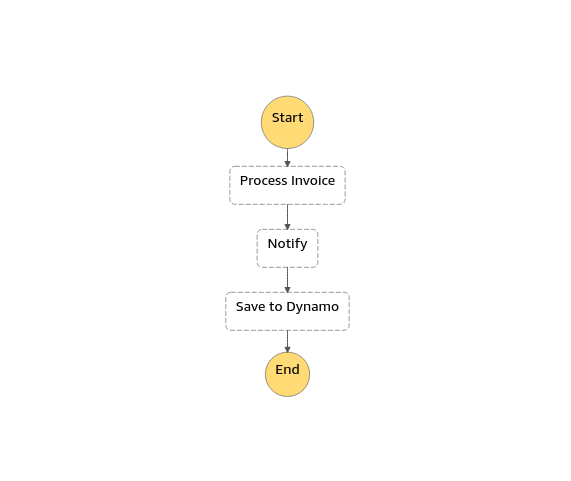
As a side note – during the development of the actual project, we encounter some problems at this level. They were caused by how data was formatted, and we could spot and solve the issue by looking into the Step Function execution at the Graph view at each task Input and Output data. So, if you find yourself in a similar situation, you can easily find the problem by looking at those details.
We built the delivery pipeline using Terraform cloud. I found it straightforward, but you can use Jenkins or other tools. You may also want to check this article: “How to structure repositories for Terraform workspaces“
If you are planning to use the Terraform cloud, you need to follow these steps.
- Create a new project and workspace in the TF cloud.
- When creating the workflow, you need to choose the version control one.
- Connect your GitHub account.
- In Terraform working directory, type the name of the folder specific to that environment – For example, we will use “devel” for the devel environment,
- Create two variables: AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY, with your connection data – mark those as sensitive.
When you push something on Github, the devel folder – (the devel environment), the TF cloud will do the plan & apply for you. (you can also trigger a manual deployment)
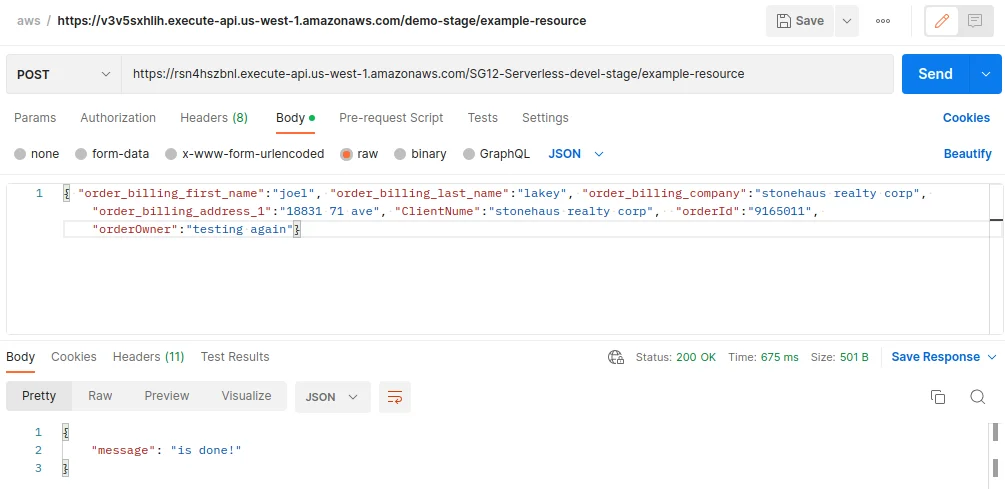
To test the whole deployment, you can call the API invoke URL in Postman and send some data in JSON format (make sure you have “orderId” and “orderOwner” fields since we check for those).