
There are situations when you need to ingest and process large volumes of data in near real-time. For example, you could have a fleet of IOT devices that sends telemetry data back to you (something like a fleet of Tesla cars that sends data back to HQ), or you have a large number of data generators that send a constant stream of data ( for example a chain of supermarkets that track sales in real-time).
In both situations, you should design an infrastructure capable of ingesting, processing, and storing this data for further analysis.
The architecture described in the following article is inspired by an actual project where one of our clients has a constant stream of data that he needs to be processed and stored. Although our sample code is minimalistic (does not cover authentication, authorization login, etc.), it can be used as a starting point for similar data processing flows.
In the AWS ecosystem, one set of applications can help you with the real-time ingestion and processing of large volumes of data. These are the three Kinesis services: Kinesis Data Streams, Kinesis Data Firehose, and Kinesis Data Analytics. In addition, these services are fully managed and serverless – so you will only pay for the resources you consume.
Here is the final architecture diagram – I will continue the article with explanations and use this image as a reference.

The Github for the demo code is here: https://github.com/crerem/serverless-kinessis-s3-terraform
To ingest the data, you have two options Kinesis Streams or Firehose. For our project, we chose to consume the data with Firehose since it’s a more straightforward service with all the options we need. However, for your project, do a comparative analysis and pick the service that suits you best.
You could use these two services as the entry point on your system, and it will work fine. However, is better to proxy them with an API Gateway. Then, the client/data emitter will send the data to the API Gateway endpoints and load them on the Kinesis Firehose.
There are several reasons for proxying the Kinesis services with an API Gateway. The first one is that it makes connecting web or mobile clients easier and lets you decouple API calls from the backed. If you don’t use an API Gateway, you may have to write different functions for mobile Android, OS, web clients, etc.
Having an API endpoint where you can send all the data will make it much simpler and will help a lot if you decide to change the downstream architecture in the future.
Another advantage is that you can use the API gateway for authentication and authorization, adding another security layer to your Kinesis layer. It is also highly scalable, can split the data into multiple streams, and provides real-time monitoring and logging for incoming requests.
Once the stream reach Kinesis Firehose, we may want to transform or trim the data. Then, you can send the data to a lambda function, where you can do some processing.
Kinesis Firehose can also perform record format conversion on the fly before writing to a data store. After processing, we will store the data in an S3 bucket.
Now, our data is ingested and in storage. But in most real-case situations, the data processing flow does not stop here. For example, you could update this process by introducing a Kinesis Data Analytics application that lets you do real-time analysis of the data using SQL or Apache Flink.
For example, you may choose to enrich the records or filter them. We will not be going into what you can do with the live analytics since this is not the scope of the article. However, you should know that besides live analytics, you have another data processing layer.
The Data analytics can output the processed stream into another Kinesis Firehose (or Kinesis Data Stream). So we deployed a second Firehose but this time without the processing lambda. This second delivery stream will save the data into another S3 bucket.
In the end, you will end up with two buckets – one containing the raw ingested data (maybe with some processing via the Lambda function) and the second one collecting the data that pass through Kinesis Data Analytics. The final batch is filtered and saved into a different format – you will see how later.
The data from the final S3 is then available for further analysis via tools like Amazon Athena. Alternatively (as you will see in the second part), you may want to send the transformed data to a data warehouse like Amazon Redshift for further analytics.
With the overall architecture drawn and explained, it’s time to move on to the coding.
We will do this using Terraform – a tool that lets you deploy infrastructure as code. I assume you are already familiar with Terraform, and you may want to check the article “How to structure repositories for Terraform workspaces” since I will not cover the actual deployment pipelines.
Our code is structured into modules containing various components of this architecture and the files in the project root folder. You can get the working code from this GitHub repo.
But, first things first. Let’s start with data generation.
Since we cannot give you access to our actual data provider, we develop a small python script to generate a data stream. This script can be found on GitHub and is called data-generator.py.
It requires the Api Gateway Endpoint and the name of the first Kinesis data stream to function. So, first, you will need to deploy the whole infrastructure(validate, plan, apply), do the code changes, and after that, you will be able to run the script.
Moving on – In the variables.tf we declared some input variables (like AWS region, application name, cloud workspaces if you want to use Terraform cloud, etc.)
In the main.tf file, we start by declaring our modules (each module has a main.tf, a variables.tf, and an outputs.tf ).
The first is the “api-gateway,” which declares our API and two endpoints. There is a lot of code in there, but special attention should be given to the ones that handle the aws_api_gateway_integration
resource "aws_api_gateway_integration" "streams_get" {
rest_api_id = aws_api_gateway_rest_api.api.id
resource_id = aws_api_gateway_resource.api.id
http_method = aws_api_gateway_method.streams_get.http_method
integration_http_method = "POST"
type = "AWS"
uri = format(
"arn:%s:apigateway:%s:firehose:action/ListDeliveryStreams",
data.aws_partition.current.partition,
var.AWS_REGION
)
credentials = aws_iam_role.api-gateway-to-kinesis-role.arn
request_parameters = {
"integration.request.header.Content-Type" = "'application/x-amz-json-1.1'"
}
request_templates = {
"application/json" = jsonencode({})
}
}
And
resource "aws_api_gateway_integration" "records_put" {
rest_api_id = aws_api_gateway_rest_api.api.id
resource_id = aws_api_gateway_resource.api.id
http_method = aws_api_gateway_method.records_put.http_method
integration_http_method = "POST"
type = "AWS"
uri = format(
"arn:%s:apigateway:%s:firehose:action/PutRecord",
data.aws_partition.current.partition,
var.AWS_REGION
)
credentials = aws_iam_role.api-gateway-to-kinesis-role.arn
request_parameters = {
"integration.request.header.Content-Type" = "'application/x-amz-json-1.1'"
}
}
Please note that for API Gateway to work with Kinesis, you need to use the “application/x-amz-json-1.1” as the header content type.
Another point of interest is the URI parameter that calls the endpoint Kinesis API for that respective API Gateway method:
- To “get streams,” use “firehose:action/ListDeliveryStreams”
- For” loading streams,” use “firehose:action/PutRecord”
Other than that, you should look over the Role policies and make them more restrictive.
The second module we deploy is the “kinessis-data-firehose”. Here is the code for the first Kinesis Firehose that receives the API Gateway data.
The code is listed below:
resource "aws_kinesis_firehose_delivery_stream" "extended_s3_stream" {
name = "sg12-kinesis-firehose-extended-s3-stream"
destination = "extended_s3"
extended_s3_configuration {
role_arn = aws_iam_role.kinesis_firehose_role.arn
bucket_arn = aws_s3_bucket.bucket.arn
buffer_interval = 60
buffer_size = 5
processing_configuration {
enabled = "true"
processors {
type = "Lambda"
parameters {
parameter_name = "LambdaArn"
parameter_value = "${aws_lambda_function.lambda_processor.arn}:$LATEST"
}
}
}
cloudwatch_logging_options {
enabled = "true"
log_group_name = "sg12/kinesisfirehose/kinesis-firehose-extended-s3-stream"
log_stream_name = "customstream"
}
}
This code declares the “data destination” as an S3 Bucket using destination = “extended_s3”. You could send data to redshift by using “destination = “redshift” or elastic search by using destination = “elasticsearch”.
Since we are using a processing Lambda function, we also declare a lambda function.
data "archive_file" "zip" {
type = "zip"
source_file = "${path.module}/hello.py"
output_path = "${path.module}/hello.zip"
}
resource "aws_lambda_function" "lambda_processor" {
filename = data.archive_file.zip.output_path
source_code_hash = filebase64sha256(data.archive_file.zip.output_path)
function_name = "firehose_lambda_processor"
role = aws_iam_role.lambda_iam_role.arn
runtime = "python3.8"
handler = "hello.lambda_handler"
timeout = 60
}
And will tell Kinesis to use that for processing by setting “processing” parameters.
In the actual Lambda code (see hello.py in the same module folder), we do “demo” data modification by adding a new set of key-pair values called “EXTRA2,” where we multiply the fuel_consumption value with the “lap_time.”
Then we encode the new data and send it down the line.
The following module is the “kinesis-data-analytics” one, where we declare our SQL analytics application using the resource “aws_kinesis_analytics_application”.
Please note that we set the start_application parameter to false. That means your application will not process data; you must start it manually (we did that for cost control).
In there, we also process our input data using this SQL statement
code = <<-EOT
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ("speed" DOUBLE, "rpm" INTEGER, "gear" INTEGER, "throttle" DOUBLE);
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM "speed", "rpm", "gear", "throttle"
FROM "sg12_prefix_001"
WHERE "speed" >= 200;
EOTThis code creates a delivery stream called “Destination_SQL_Stream” and a SQL Pump to load the data if the “speed” value is over 200.
Kinesis Data Analytics SQL Pump is a feature of Amazon Kinesis Data Analytics that enables users to extract data from a Kinesis data stream, transform it using SQL queries, and load it into another Kinesis stream.
Further down the code, we have here a long input schema definition for our entry date and our output definition.
outputs {
name = "DESTINATION_SQL_STREAM"
schema {
record_format_type = "CSV"
}
kinesis_firehose {
resource_arn = var.KINESIS_OUTPUT_FIREHOUSE_ARN
role_arn = aws_iam_role.kinesis_analytics_role.arn
}
}With that code, we send the data into CSV format to the second Kinesis Firehose (module module “kinesis-data-firehose-after-analytics”) that will save the data in the “sg12-tf-processed-bucket”
Now that we covered the code, you can validate, plan and apply the terraform code. Once the infrastructure is deployed, you can proceed with a test run.
Start by changing the data-generator.py code and adding your API endpoint URL. After that, you can start the script.
After 60 seconds(our buffer timeout), you should be seeing into the first bucket files like
sg12-tf-initial-bucket2023/03/25/10/sg12-kinesis-firehose-extended-s3-stream-1-2023-03-25-10-24-31-a0853f54-ad76-42ff-8ce3-956701fd8ffdWhere data is stored in this format
{"speed": 190.4740611874923, "rpm": 15251, "gear": 2, "throttle": 0.9408792285559685, "brakes": 0.43357872501086275, "steering_angle": -0.45486734518890914, "suspension": {"ride_height": 35.9599644358097, "damper_settings": {"front_left": 7.408169579100961, "front_right": 10.944175941334308, "rear_left": 4.2780159746757676, "rear_right": 4.756502872556679}}, "temperatures": {"engine": 98.87748639033923, "brakes": {"front_left": 243.94481990558253, "front_right": 232.11554644093226, "rear_left": 202.704610220406, "rear_right": 217.1034676852164}, "tires": {"front_left": 93.27847514872009, "front_right": 92.64261929429316, "rear_left": 83.32364209856682, "rear_right": 110.3259619126771}}, "pressures": {"engine": 4.2, "brakes": {"front_left": 18, "front_right": 17, "rear_left": 16, "rear_right": 15}, "tires": {"front_left": 1.7, "front_right": 1.8, "rear_left": 1.9, "rear_right": 1.8}}, "fuel_consumption": 2.4, "lap_time": 75.6, "EXTRA2": 181.43999999999997}** note the EXTRA2 key/pair
Start your Kinesis Data Analytics application and review the “Configuration” – you will see the live query editor.

Also, you could see the live data in
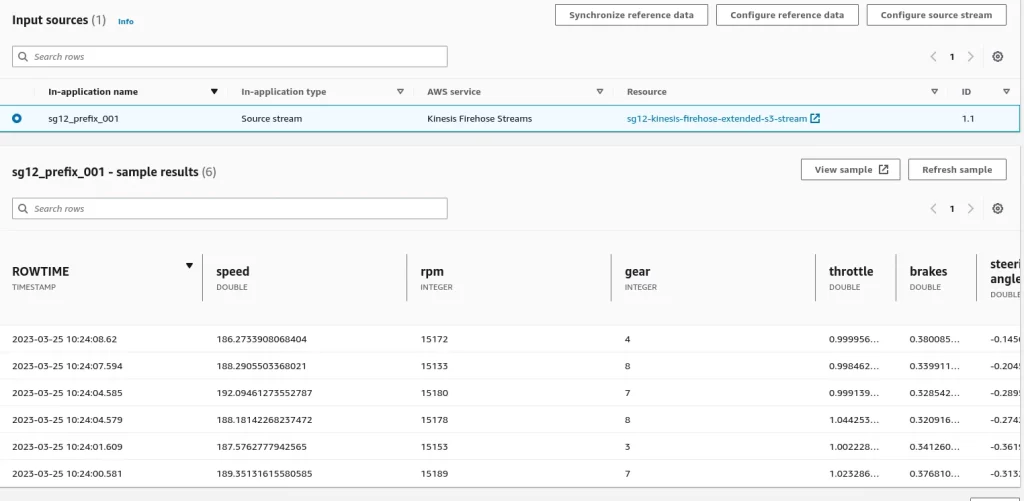
And if you look over the destination tab, you will see the output data.

In the end, if you look into the “sg12-tf-processed-bucket” bucket, you will see the transformed records.
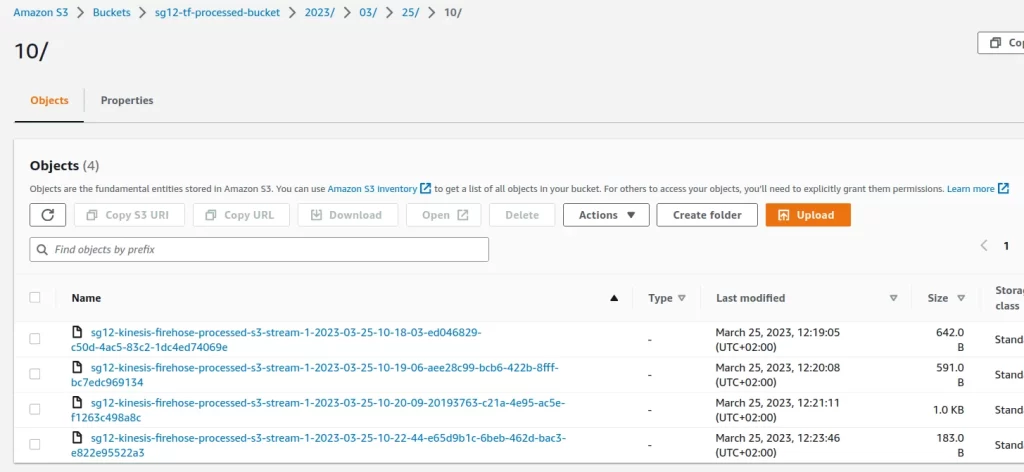
If you open one of those files, you will see the data is processed and saved into a CSV format:
203.1421738761125,14920,1,0.7467483464804441
205.77418581463328,14969,3,0.7492183424047895
201.26150376705385,14964,5,0.7374675365104493
201.93043116177444,14938,4,0.6993241454656731Now that our data processing flow is deployed and functional, we will end this article. However, we continue to evolve this architecture; you can read about that in the next part: “Serverless data processing flow with Kinesis Data Firehose – part2, adding a Redshift Cluster“


